
이야기박스
Spark Appendix. RDD vs Dataframe vs Dataset 본문

# 개요
[Databricks 공식 문서; A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets]의 해석본입니다. 각종 오역이 난무할 수 있습니다.
위 글은 spark 2.2 이후의 내용을 다루고 있고 RDD, DataFrame, Datasets의 API 관점에서 작성되었습니다.
특히, spark 2.0에서 Dataframe과 Datasets이 통합되었기 때문에 이 두 API의 내용이 많습니다.
두 데이터 API를 통합한 이유는 Spark API를 간결하고 쉽게 하기 위해서 Structured Data 처리 방법을 하나로 제한하였기 때문입니다.
이렇게 하나의 구조화된 처리는 Spark의 높은 추상화를 제공하고 이는 다양한 언어에서 Spark 사용이 가능하게 한 원동력이 되었습니다.
# Summary
높은 수준의 추상화를 원한다면 DataFrame, Dataset을 사용하여라.
그리하면 사용하기도 쉽고, 최적화도 얻을 것이니라. by Catalyst optimizer, Tungsten
# RDD
Immutable distributed collection of your data, partitioned across nodes in your cluster.
클러스터 내 각 노드에 여러 파티션으로 분산되어 있습니다. 그리고 이들은 불변의 특징을 갖습니다.
여기서 말하는 불변은 스파크의 Lazy한 동작으로부터 발생하는 특성을 의미합니다. `이야기박스 Fundamentally lazy 참조`
RDD는 위 두 특성을 바탕으로 Low level API(Transform, Action)를 모든 파티션에 병렬로 제공할 수 있게 됩니다.
## 언제사용하는가?
- Low-level transformation, actions 처리할 때
- Unstructured data
- Functional Programming으로 처리하고 싶을 때
- 스키마 신경 쓰고 싶지 않을 때
- Structured, Semi-Structured 데이터 처리 시, DataFrame, Dataset으로 얻을 수 있는 이점을 포기해도 될 때(Optimization, Performance)
## spark 2.0 이후, 없어졌을까?
초기 스파크의 데이터 단위이지만, 여전히 잘 사용되고 있습니다.
왜냐하면, API를 통해 DataFrame, Dataset, RDD 이동이 자유롭고 위와 같이 여전히 RDD의 사용이 필요한 경우가 있기 때문입니다.
DataFrame, Dataset은 RDD를 바탕으로 만들어 짐
# DataFrames
RDD와 마찬가지로 Immutable하며, 파티션에 나뉘어 있습니다.
다만 DataFrame은 RDB와 같은 컬럼 구조를 갖는 Structured 데이터라는 점에서 차이가 있습니다.
Structured 데이터는 개발자가 분산되어 저장된 데이터에 구조를 적용할 수 있게 하고 이는 즉 높은 수준의 추상화 처리가 가능하게 됨을 의미합니다. 우리는 이러한 추상화로부터 커다란 데이터 처리를 보다 쉽게 할 수 있게 됩니다. 예로 이 추상화는 다양한 언어의 API 지원을 가능하게 하죠.
DataFrame API는 Spark 2.0 이후로 Datsets API에 통합되게 됩니다.
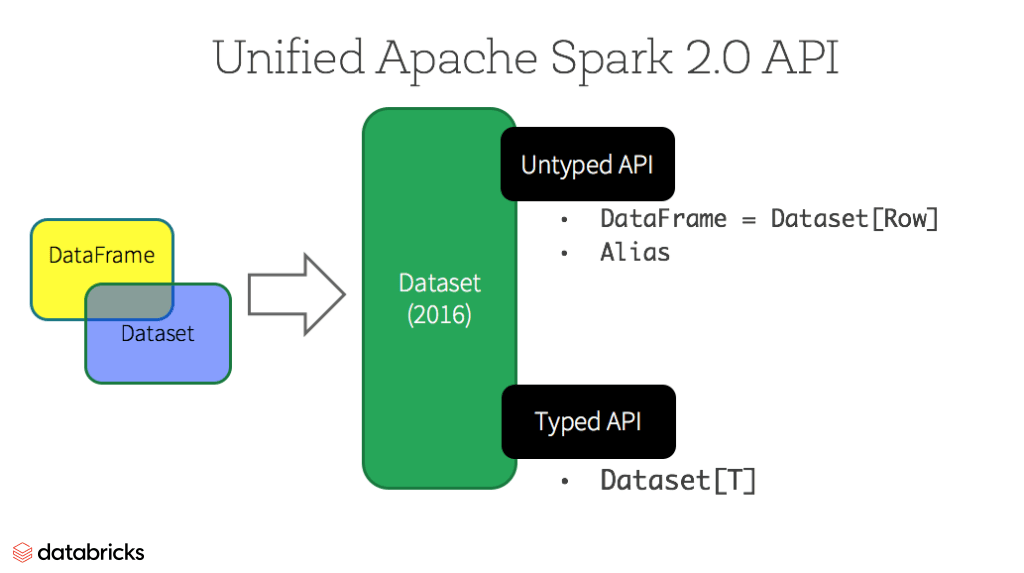
# Datasets
위에서 말한 2.0 통합으로 Dataset API는 두 가지 특징을 갖게 되었습니다.
## 기존 DataFrame의 untyped API
스키마의 타입이 정의되지 않고 Generic 타입으로 데이터 구조가 형성됩니다. 이를 Spark에서는 아래와 같이 표현합니다.
DataFrame = Dataset[Row]
`Row` : generic untyped JVM objects.
## 기존 Dataset의 Strongly-typed API
Scala, JAVA에서 정의되는 Strongly-typed JVM objects를 사용할 수도 있습니다.
| Language | Main Abstraction |
| Scala | Dataset[T] & DataFrame (alias for Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
위 표에서 확인할 수 있듯이 Python, R과 같이 Untyped API(DataFrame)을 주로 사용하다 보니 Compile Error보다는 Runtime Error가 자주 발생하게 됩니다..
# Benefits of Dataset API
가장 최신 API, Dataset API의 장점에 대해서 알아보겠습니다.
## Static-typing and runtime type-safety
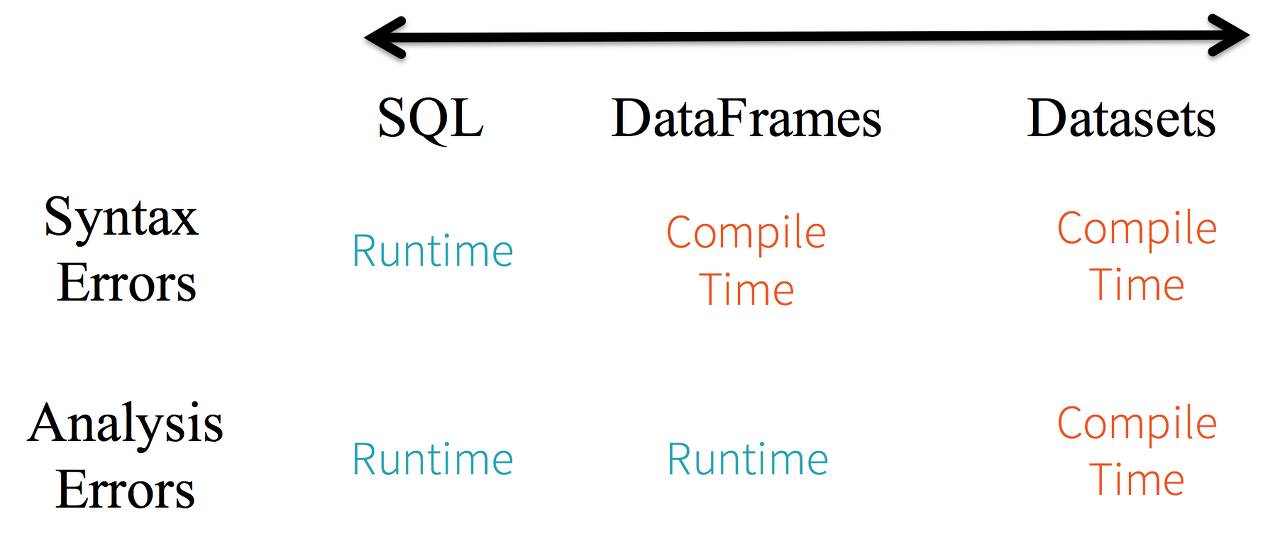
DataFrame API의 경우, JVM 타입의 오브젝트로 모든 데이터가 표현되어야 하기 때문에, 이로부터 발생 가능한 Runtime Error를 Compile 단계에서 확인할 수 있습니다.
## High-level abstraction and custom view into structured and semi-structured data
구조화 혹은 반 구조화된 데이터를 렌더링 하여 확인할 수 있습니다. 과정은 아래와 같습니다.
Step 1. 데이터를 읽고 스키마를 추론하며 DataFrames을 생성한다. 이때, DataFrame = Dataset[Row]이다. 왜냐하면, 스키마를 특정짓지 못하였기 때문
Step 2. 사전에 지정해둔 스키마를 통하여 Dataset[Row] --> Dataset[T]로 변환이 가능하다.
## Ease-of-use of APIs with structure
filter(), map() 등 편리한 API가 장점이죠. ㅎㅎ
## Performance and Optimization
Optimization
DataFrame, Dataset은 Spark SQL Engine을 바탕으로 만들어졌습니다. 이들은 Catalyst를 사용하기 때문에 논리적 / 물리적으로 최적화 쿼리를 사용할 수 있습니다. 이는 어떠한 언어를 사용하더라도 동일한 효율을 발휘합니다.
- Data engineering: Dataset[T]
- Data analysis: Dataset[Row] ( =DataFrame )
Tungsten
스파크는 컴파일러로서 동작할 때, 데이터 타입을 텅스텐 내부 메모리에 인코딩 기록해둡니다.
이로부터 효율적인 serialize / deserialize가 가능하여 속도 개선에 큰 역할을 합니다.
What is the Spark Tungsten Project? - Databricks
Tungsten is the codename for Spark’s project to make changes to the engine that focuses on improving the efficiency of memory and CPU for applications.
databricks.com
# Datasets vs DataFrames, 언제 무엇을 사용해야 할까?
- 높은 추상화의 API를 사용하고 싶은 경우 --> DataFrame, Dataset
- map, filters 등 다양한 Spark API를 사용하고 싶다면 --> DataFrame, Dataset
- type-safety를 컴파일 단계에서 확인하고 싶다면 --> Dataset
- R 사용자라면 --> DataFrames
- Python 사용자라면 --> Dataframes (+ 세심한 컨트롤이 필요하다면 RDD)
# 후기
스파크의 가장 기본이 되는 내용이니, 잘 숙지해서 넘어갑시다 ㅎㅎ
'Computer & Data > Big Data' 카테고리의 다른 글
| Chapter 4. Fundamentally lazy (0) | 2020.11.12 |
|---|---|
| Chapter 3. The majestic role of the dataframe (0) | 2020.10.22 |
| Chapter 8. Ingestion from databases (0) | 2020.08.06 |
| Chapter 7. Ingestion from files (0) | 2020.08.06 |
| Chapter 6. Deploying your simple app (0) | 2020.07.30 |


