
이야기박스
Hadoop 시리즈. Hadoop Ecosystem 본문

오늘은 하둡 에코시스템에 대하여 간단하게 정리하는 글을 갖고, 앞으로 여유가 생길 때마다 하둡 구성원들을 하나씩 정리해서 포스팅하도록 하겠습니다.
하둡이란?
대용량 데이터를 여러 컴퓨터에 분산시켜 처리할 수 있는 자바 기반의 오픈 소스 프레임워크
2006년, 야후의 더그 커팅으로부터 비정형 빅데이터 처리를 위해 구글에서 발표한 GFS와 MapReduce 논문을 참조하여 개발되었으며, 이후 아파치 재단의 오픈 소스로 공개되었습니다.
Hadoop Ecosystem
ecosystem; 생태계. 상호작용하는 유기체들과 또 그들과 서로 영향을 주고받는 주변의 무생물 환경
하둡이 자바 기반의 분산처리 프레임워크라고 바로 위에서 말씀드렸죠. Hadoop Ecosystem이란 하둡을 구성하고 있는 수많은 하위 프로젝트들로 구성된 생태계라고 보면 됩니다.
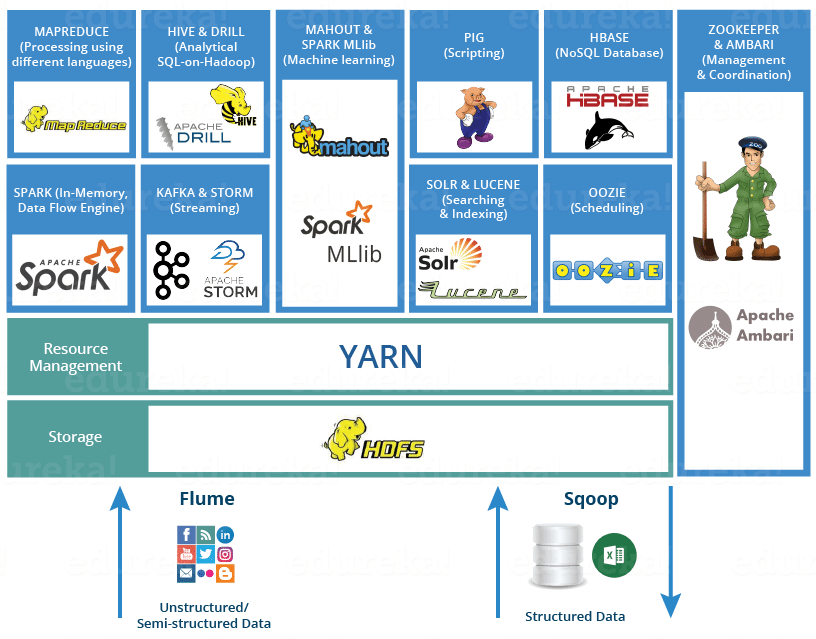
HDFS (분산 데이터 저장)
Hadoop Distributed File System의 약자로 하둡의 핵심 기술 중 하나입니다.
하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일 시스템을 가지고 있고 분산된 데이터는 여러 서버에 복사본을 만들어두기 때문에 높은 가용성을 가지고 있습니다.
또한 Hadoop Ecosystem의 구성원이기 때문에 자바로 개발되었습니다.
MapReduce (분산 데이터 처리)
대용량 데이터 처리를 위한 분산 프로그래밍 프레임워크입니다. 제 주변분들은 줄여서 'MR'이라고 부르더라고요.
Map과 Reduce 두 개의 함수로 나누어져 있고 이들은 다음과 같은 특성을 가집니다.
- Map: filtering, grouping and sorting
- Reduce: aggregates and summarizes
YARN (자원 관리)
MapReduce의 속도 문제 해소를 위해 새롭게 개발된 자원 관리 서브 프로젝트입니다.
MapReduce는 Tracker로부터 발생하는 성능 이슈가 있었는데, 이 때문에 RDB에 익숙한 사람들이 하둡을 싫어했다고 하네요. 이 문제를 해결하기 위해 YARN이 도입되었다고 하네요.
YARN이 도입된 지금도 RDB에 비하면 데이터 조회 속도가 어마어마하게 느리죠.. 이전에는 더욱 심했을 거기 때문에 하둡 1.0에 대한 거부감이 심했을 것이라 생각됩니다.
YARN이 도입된 이후의 하둡을 2.0이라고 정의합니다.

HBase (분산 데이터베이스)
하둡에서 제공하는 NoSQL 데이터베이스입니다. 구글의 BigTable 논문을 기반으로 개발된 자바 프로젝트라고 합니다.
Hive (SQL 조회 시스템)
SQL에 익숙한 사용자들을 위해 HiveQL을 제공하는 `SQL On Hadoop` 시스템입니다. 하지만 이 HiveQL은 표준 SQL(Ansi SQL)과는 문법이 조금 다르다는 문제점을 가지고 있습니다.
Zookeeper (분산 코디네이터)
분산 환경에서 서버 간의 조정이 필요할 때, 이들을 위한 조정 시스템입니다. 주요 동작은 다음과 같습니다.
- 하나의 서버에 트래픽이 몰리지 않도록 조정
- 하나의 서버에서 처리된 데이터를 다른 서버들과 동기화
- Fault Tolerance. 하나의 서버에서 장애가 발생해도 다른 예비 서버에서 서비스
Kafka (실시간 데이터 관리)
스트림으로 들어오는 실시간 데이터를 관리하기 위한 분산 메시지 큐입니다.
Flume, Chukwa, Sqoop, Scribe (데이터 수집)
모두 분산 환경에서 데이터를 안정적으로 수집하기 위한 서브 프로젝트입니다.
- Apache; Sqoop, Chukwa
- Cloudera; Flume
- Facebook; Scribe
이중에 Sqoop만 정형 데이터 수집을 위한 기술이고 나머지는 비정형 데이터 수집 기술입니다.
후기
Hadoop Ecosystem이란 무엇인지, 간단하게 살펴보는 포스팅을 작성하기 위해서 각 서브 프로젝트는 가볍게 훑고 지나갔습니다. 이후에 [Hadoop 시리즈.]로 하나씩 자세하기 포스팅하도록 하겠습니다.
참조
Hadoop Tutorial | Getting Started With Big Data And Hadoop | Edureka
Hadoop tutorial introduces you to Apache Hadoop, its features and components. It re-directs you to complete Hadoop Ecosystem in detail.
www.edureka.co
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
'Computer & Data > Big Data' 카테고리의 다른 글
| Hadoop 시리즈. Zookeeper 설치 (0) | 2021.04.23 |
|---|---|
| Hadoop 시리즈. HDFS 맛보기 (1) | 2020.11.20 |
| Chapter 4. Fundamentally lazy (0) | 2020.11.12 |
| Chapter 3. The majestic role of the dataframe (0) | 2020.10.22 |
| Spark Appendix. RDD vs Dataframe vs Dataset (0) | 2020.10.22 |



