
이야기박스
Kafka Broker의 내부 동작 방식 본문

정말 오랜만에 기술 글입니다. 이번 포스팅은 링크드인에서 읽었던 카프카 글을 번역하는 느낌으로 작성해 보았습니다.
Summary
- 카프카 브로커는 아파치 카프카의 중심 구성 요소로 메시지를 수신, 저장 및 전달하는 허브 역할을 합니다.
- 카프카 브로커는 토픽, 파티션 및 복제본을 관리하여 Fault Tolerance와 확장성을 보장합니다.
- 카프카 브로커는 네트워크 스레드, I/O 스레드, 커밋 로그 및 Purgatory와 같은 구성 요소를 포함하는 Producing 및 Fetch 요청을 처리합니다.
- 카프카 브로커를 이해하는 것은 신뢰할 수 있고 확장 가능한 메시지 저장 및 전달 시스템을 구축하는데 필수적입니다.
What is a Kafka Broker?
아파치 카프카의 브로커는 카프카의 핵심 구성요소입니다. 서버로써 동작하며 메시지를 수신하고 저장하며 이를 Consumer에게 전달하는 허브 역할을 합니다.
흔히 "회사에서 카프카를 운영한다!" 하면 카프카 브로커를 운영하는 것과 다름이 없습니다. 아무리 카프카를 오래 다루었던 사람이라도 브로커에 대하여 제대로 설명하지 못한다면 그 사람이 운영하는 카프카 클러스터에 대한 신뢰도는 많이 떨어지게 될 것입니다.
카프카 브로커에 대하여 알아보기 전에 브로커의 사전적 의미 먼저 보고 넘어가겠습니다.
Broker; a person who buys and sells foreign money, shares in companies, etc., for other people:
브로커는 우리말로 하면 중개자라는 뜻이며, 카프카에서는 Producer와 Consumer라는 데이터 생산/소비자에 대한 중개 역할을 하고 있습니다.
Kafka에 대한 간략한 개요
자세한 내용은 다른 포스트에서 다룰 수 있다면 거기서 작성하겠습니다. 이번 포스트는 아래 글들을 이해하는데 도움 되는 수준으로만 작성합니다.
Leader / Follower
Leader는 Producer / Consumer와 직접 통신하는 파티션을 의미합니다.
Follower는 복제 데이터를 가지고 있는 파티션을 의미합니다.
Control / Data Plane
Control Plane은 Kafka 클러스터의 메타데이터를 다루며 브로커의 상태를 체크하며 트래픽 제어, 접근 제어, 거버넌스, 보안 및 모니터링과 같은 측면을 전담합니다.
Data Plane은 실제 데이터가 존재하는 영역이며, 비즈니스 트랜잭션에 처리되는 부분입니다.
실험 방식
우리는 카프카 브로커의 동작 방식 이해를 위하여 Producer가 카프카에 레코드를 제출하는 것을, 그리고 Consumer가 카프카에서 레코드를 읽는 과정을 상상해볼 예정입니다. 각각의 요청이 발생하였을 때, 카프카 브로커의 내부에서는 어떠한 일들이 일어나는지 확인해 봅니다.
Partition 할당
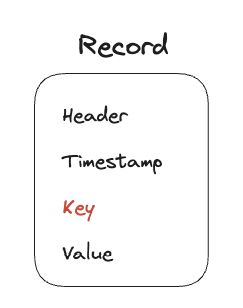
카프카의 레코드는 Header, Timestamp, Key, Value 4개의 구성요소로 이루어져 있습니다. 이때 Producer가 데이터를 카프카에 전송하면 Key에 의하여 저장 파티션이 결정되게 됩니다.
Key가 제공된다면 Key의 Hash 정보가 파티션 할당에 활용되게 됩니다. 반대로 Key가 제공되지 않는다면 Round-Robin 알고리즘에 의하여 파티션이 결정됩니다.
이제 파티션이 할당되었습니다. 다음 동작을 살펴보겠습니다.
Network Threads
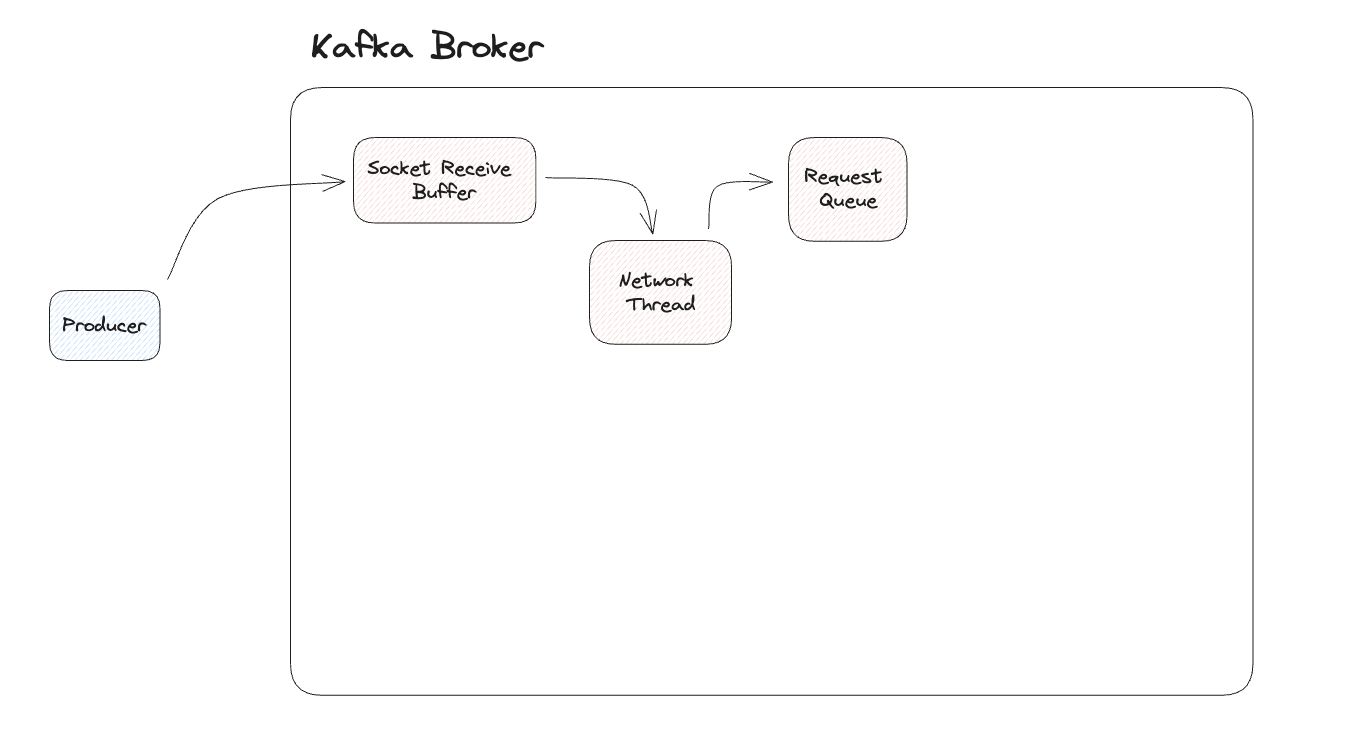
Producer의 요청은 브로커의 Socket Receive Buffer에 들어오게 됩니다. 이 요청은 Network Thread를 거쳐 Request Queue에 저장 됩니다. 이 과정에서 요청은 Produce Request Object로 변환되어 전달됩니다.
I/O Threads
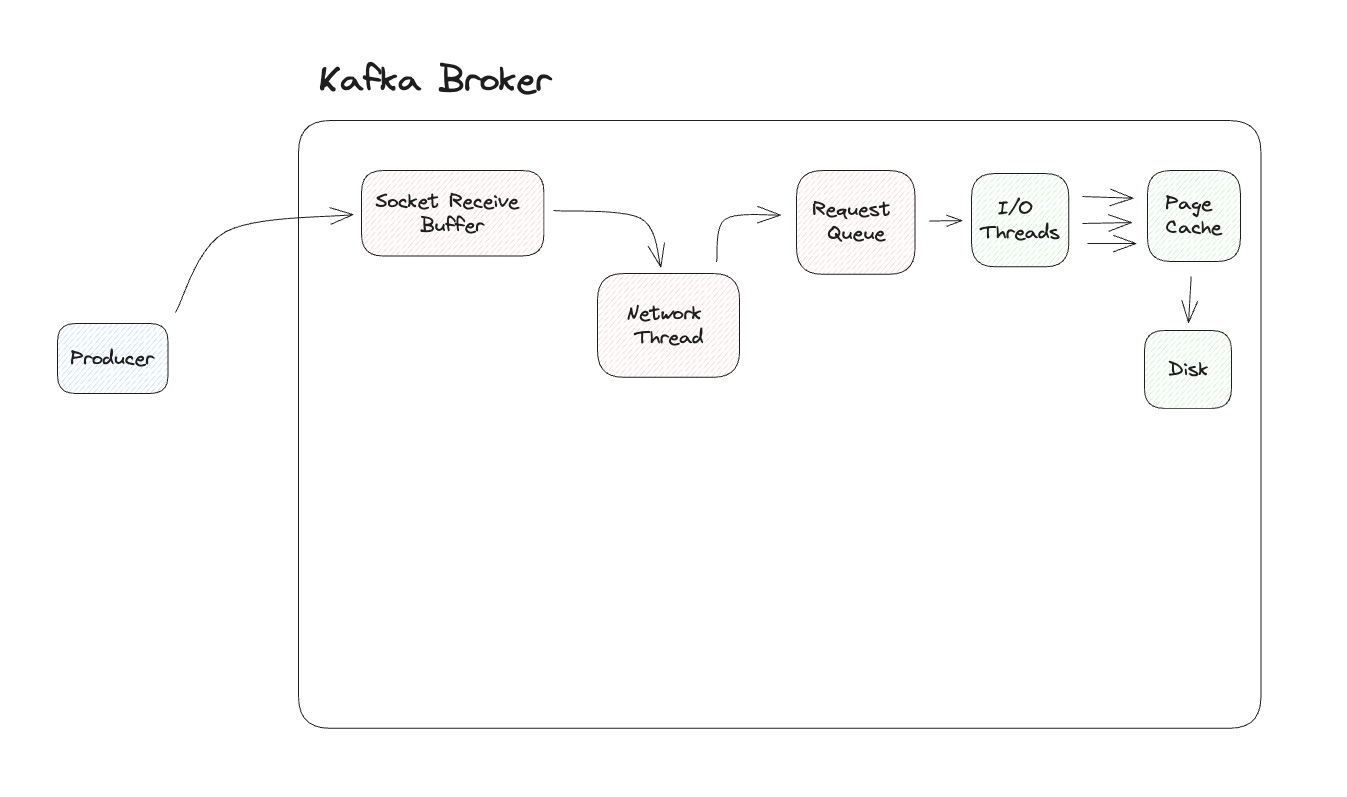
Request Queue에 들어온 Object를 I/O Threads에서 읽고 물리적으로 파일을 추가하기 이전에 Data integrity, Format compliance, Custom Business Logic과 같은 각종 유효성 검사를 진행합니다. 이러한 검사를 통과하면 I/O Thread는 Commit Log 파일을 디스크에 저장하게 됩니다.
Purgatory
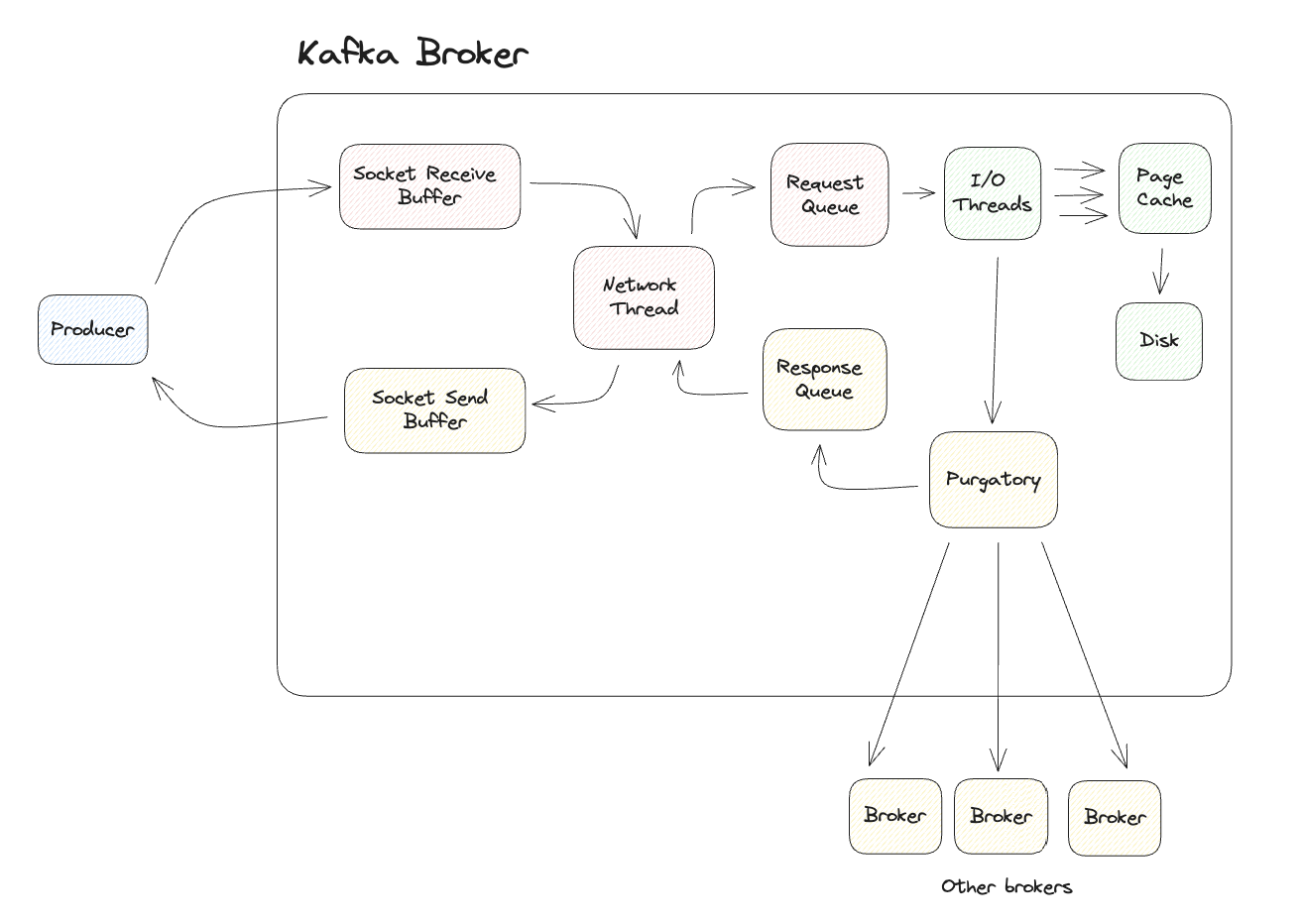
레코드의 저장이 실제로 완료되기 전까지 브로커는 Ack를 주지 않습니다. 이로 인해 I/O Threads에 대한 병목이 발생할 수 있는데, Kafka에서는 Purgatory라는 Map 구조를 통하여 이를 해소하였습니다.
Purgatory(연옥)이란?
하느님의 은총과 사랑 안에서 죽었기 때문에 영원한 구원을 보장받았으나 완전히 정화되지 못했기 때문에, 하늘의 기쁨으로 들어가기에 필요한 거룩함을 얻기 위해 일시적인 정화를 거치는 상태를 말한다.
I/O Thread는 Purgatory에 오브젝트를 기록하고 다음 작업을 진행합니다. Purgatory에 기록된 오브젝트는 모든 브로커에 복제할 때까지 Response Queue에 오브젝트를 보내지 않는데, 이때의 중간 대기 상태를 표현하기 위하여 Purgatory라는 용어를 사용한 것으로 보입니다.
복제가 완료되면 Response Queue에 기록되고 응답 객체를 Network Thread를 통하여 Socket Send Buffer로 보냅니다.
Socket Send Buffer에 기록된 응답은 Producer에게 전달되며 이로 인해 일련의 Producing 작업은 마무리됩니다.
Consuming (Fetch)
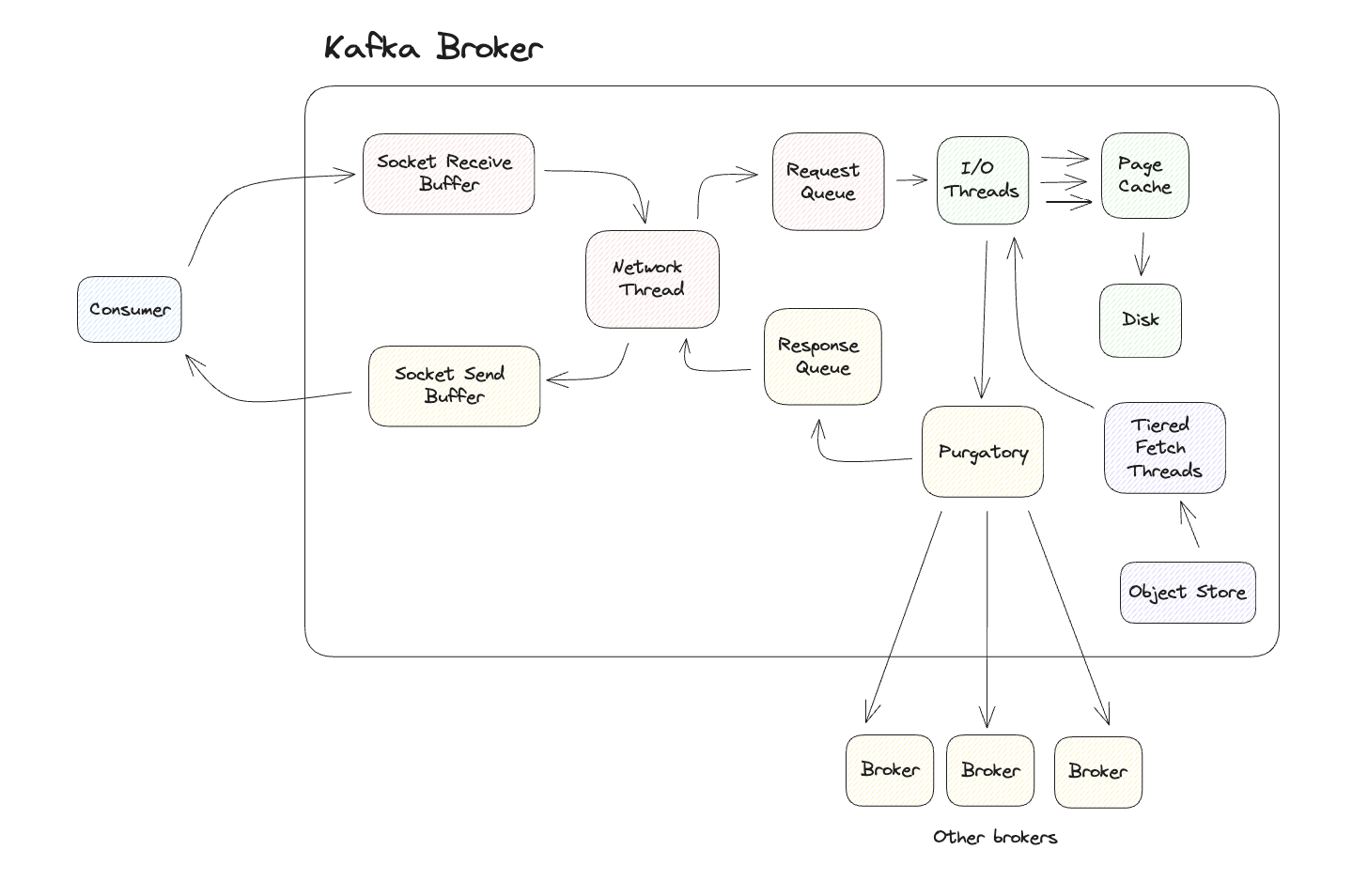
Producing과 비슷한 흐름을 보입니다. Consume에 대한 요청은 Socket Receive Buffer에 요청이 들어가고 Network Thread를 통하여 Requeset Queue에 저장됩니다.
I/O Threads는 Fetch Request에 포함된 Offset 정보를 읽어 이를 파티션 정보를 담고 있는 .index 파일과 비교합니다. 이 때, .log 파일에서 읽고 응답할 개체에 추가할 정확한 바이트 수를 결정합니다.
Consumer는 읽을 수 있는 바이트의 수, 최대한 기다릴 시간 두 가지 조건을 설정할 수 있습니다. 이를 바탕으로 Fetch Request는 두 조건이 충족될 때까지 Purgatory에서 작업을 수행하며 기준이 충족된다면 Response Queue, Network Thread, Socket Send Buffer를 거쳐 Consumer에게 응답을 주게 됩니다.
후기
근 2년 만에 카프카에 대한 문서를 읽어보았습니다. 최근에는 zookeeper를 제거하고 Kraft를 활용한 코디네이팅을 한다고 합니다. 카프카에 대한 기술도 큰 변화가 있었고, 오랫동안 공부를 하지 않아 잊어버렸던 내용들을 다시 되짚어보려고 합니다.
오늘 포스팅에 나왔던 내용들은 각각 다른 포스트로 좀 더 자세하게 다루어 보려고 합니다.
그럼 다음에 뵙겠습니다.
'Computer & Data > Big Data' 카테고리의 다른 글
| Redis. Deploy on Kubernetes with helm (1) | 2022.09.24 |
|---|---|
| Redis 컨테이너 환경 실행 with Docker-compose (0) | 2022.09.12 |
| Redis High Availability; Sentinel vs Cluster (4) | 2022.08.20 |
| What is Redis; Remote Dictionary Server (0) | 2022.08.20 |
| Elasticsearch - RestHighLevelClient를 통하여 대량의 문서를 조회하기 (0) | 2022.05.18 |



